
Case Study - Deutsche Börse
In 2022, Deutsche Börse set out to give the best possible information to firms placing trades on its exchange. ReportLab was selected to develop the reports and graphics.

Deutsche Börse (henceforth “DB”) is Germany’s major stock exchange, and the financial heart of the European Union. It competes against a number of other stock exchanges, and other off-exchange means of trading such as the infamous “dark pools”, all of which can trade in German stocks. There are about 200 direct participants in the exchange, range from super-sophisticated high frequency traders to local banks.
Stefan Schlamp, Head of Quantitative Analytics at DB, says…
“A couple of years ago, we heard from our participants that we were falling short in terms of analytics. We were giving them very little feedback on how they were doing and how they could improve their performance. We wanted to develop something which gives all the participants some interesting new information which they could not already get from public sources. The super-sophisticated ones could do a lot of analysis using public data, but we wanted something new for everyone.
The analytics was fairly easy; we all have access to the database and can all code. But we weren’t graphical or UI specialists. ReportLab came in to make the step from the numbers to the graphical output. We needed something which would scale, and reliably do this for hundreds of reports.
The reports are now generated monthly or quarterly for all of the participants, and shared with clients by their advisers.
The first prototype live reports were created in Q4 2023, and after review this was rolled out to all clients in Q1 2024.
We’re now extending this to EUREX, the derivatives exchange, and EEX, the European Energy Exchange where gas, power, emissions and other energy products are traded; these are all based on the same platform”
The solution
A lengthy PDF report - around 40 pages - is produced for every participant in the market, either monthly or quarterly. This is carefully and professionally branded, with cover, dynamic tables of contents, and consistent typography and colours throughout. Within are many complex custom graphs, with different data for each client. The ReportLab graphics framework excels at this type of project, as we can not only produce the overall document with text and tables, but also create any data graphic as a Python program which knows how to render itself into the larger document.
The architecture
We developed a `json to pdf` solution - a directory with a top-level Python function that takes in a document structured in json, and creates a PDF in response. The overall json structure was very complex, containing numerous nested arrays with all the data to drive all of the charts and their labels. However the report architecture is very simple:
a json file is passed to a controlling function
a template in our Report Markup Language, which is similar to Jinja or any other web templating system, but describes printed page elements
top level variables such as a document title can be substituted in from the json to the document output, and we can loop and branch through the data and repeat this at any level
the relevant data for any chart can be rearranged and passed to a chart module
Specific graphics get mapped to chart classes written in our own reportlab/graphics framework. These have all the usual building blocks for all the common chart types - axes, lines, labels and so on - but our framework lets us override any element. It’s possible, for example to hide or show, or even adjust the anchor-point and angle of a single text or line label. So, creating a bespoke graphic is a lot less work for us than for anyone starting from scratch. Also, it helps massively to be using mature chart code which has generated millions of financial graphics since 2001, as generally the linex and axes will “do the right thing” when presented with highly variable data.
There is a huge amount of detail in the project, especially with some charts which attempt to pack up to four or five dimensions of data - but the overall concept is simple and it’s easy to locate where in the code a change needs to be made.
Terminology 101
This story is mostly about the complexity of the graphics and the ease of their production, but to help a little we will briefly define some terms.
Firstly, the client is interested in how they have traded but also how they differ from their peers (similar companies) and the broader market - hence the charts tend to come in threes. Participants range from banks and brokers, whose clients really want to buy or sell a specific stock through to super-sophisticated proprietary trading firms.
We divide the market into two types of participants, “aggressive” - those that want to trade now at a certain level or not at all - and “passive” - those that are willing to wait for the price they want. If you trade then your order is a “hit”, if not then it is a “miss”
The life cycle of an auction
The chart below show activity over time in a brief auction at the end of the trading day - it starts at 17:30 and runs for about 5 minutes. During this time, nobody gets any information about what other participants are bidding or offering. To add a bit of uncertainty and discourage people from “gaming the system”, nobody knows the exact ending time, which is random - this one finished 25 seconds after the 5 minute period.
This shows that the person getting the report had an order in place at the moment of opening (bottom left blue bar), as did most participants. After the first few seconds, they then placed most of their orders in the first two minutes, as did most participants, then things got quieter. Things picked up a bit in the last minute or two, and there is a second spike about 30 seconds from the end, presumably driven by people needing to trade before end of day, but not wanting to show their hands too early.

This is a very simple stacked bar chart showing two dimensions of data, one of the standard charts in our library, but it shows a couple of useful points: we can control in Python code exactly which axis labels are drawn, so that rather than showing “17:30, 17:31, 17:32, 17:33, 17:34, 17:34” along the bottom, and then a little gap on the right, as you might get from Excel, we can say “show the very last point” with the closing time of 17:35:25, if we wish.
Who are you trading with?
A big section at the back of the report aims to answer this question, with a row of three pies for each different types of security. One is shown below, for all equities.
Then, within each of these pies, the outer “doughnut” is divided up into three to show which types of organisations bought the stock they were selling, or vice versa. (With apologies to DB’s design department changed the house colours to pink for this article, to make it stand out a bit). Our participant (the leftmost chart) is hardly interacting with retail brokers, and doing most of their trading with proprietary traders.
In the centre of the pie we also display the percentage of trades with passive or aggressive counterparty.
So, these charts help firms to know what types of firms they are doing business with - something they would not normally have known before DB released this data.

We already had doughnut (“hole in the middle”) and pie charts in our library, so to implement this we stacked one on top of the other. We can control the “start angle” so all of the pies have a slide starting at 9pm on the clock face, or 270 degrees; so the data is normalised to make sure that three outer doughnut slices exactly surround one inner pie slice. This is all straightforward Python programming, adding and dividing a few numbers, as long as you have a chart library with the right hooks to do the manipulations during drawing.
If you are counting, we are now up to three dimensions of data in this one: the type of entity doing the trade, aggressive versus passive, and the type of entity on the receiving end.
Trade execution time - the fourth dimension
The next chart we’ll dissect is again specific to each client and shows various data such as miss rate (the opposite of hit rate) as a function of speed of order for the client; again compared to their peer group and the market in general; and further broken down by lead and lag.
This takes us into the world of displaying multi dimensional data. DB’s team spent a long time thinking about how to display these with a static prototype, and our job was again to bring it to life in a scalable way with real data.
A common type of order is IOC (“Immediate or Cancel”) - i.e trading quickly in response to a market event or trigger. You are basically saying “if there’s something on the market at this price right now, take it, but otherwise, I’m not going to wait for later”.
Clearly, the speed of your response is key here - if you see a bargain, you want to grab it before anyone else does.
The chart below shows one of the more complex graphics we have produced. If you bid for something and didn’t get it, do you understand why and who beat you to it? It shows a huge amount of information…
The “client entity type” - the Participant (the person getting the report); the Peer Group or Market (the groups of three bars, between each vertical line)
How quickly was the trade placed by whoever won that auction? We have five bands based on the speed (“latency regime”)
If you lost, typically how much faster was the firm that beat you (the shades of grey in each bar)? If you won, how much faster were you (shades of blue)? Or were you maybe the only competitor in a one-horse race (the green bars)?
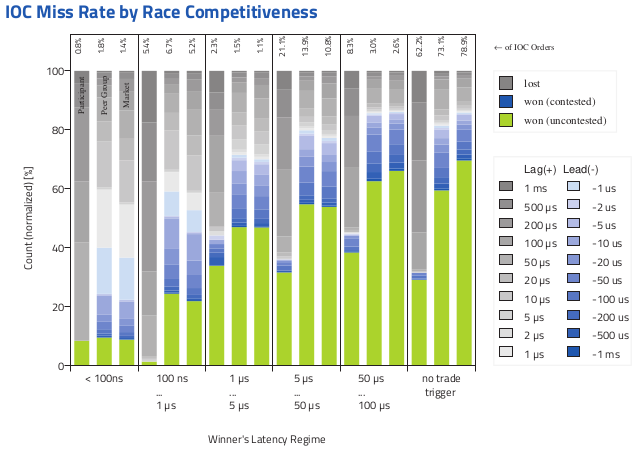
It’s fun to look at the time scales - a lot of trades are happening in less than a microsecond, and some in under 100 nanoseconds. At the speed of light, that’s 30 metres, so the trader cannot be “somewhere across town”. This is accomplished by special chips with the rules burned into them - Floating Programmable Gate Arrays - and executed by high-speed trading firms who pay to locate these directly inside the exchange, for almost instant execution.
Building a chart like this, which packs in four dimensions of data, was reasonably straightforward within ReportLab, as we are able to customise every detail and to compose “chart elements” in reasonable Python code. We took a stacked bar chart with 18 vertical bars, and we adjusted spacings and added a separator line every third line to fake the effect of “groups of bars”. We also added a secondary axis along the top, and positioned multiple legends ourselves alongside it. The hardest work was rearranging arrays in the json data and synthesizing the numbers to “flatten” those four dimensions into the correct two dimensions for the plot to work.
We recommend Michael Lewis’s book Flash Boys for a layman’s introduction to this world, and what happened ten years ago when it was not regulated so well!
Trade Sizes
On a scale of one to ten in information density, in the immortal words of the movie Spinal Tap, “this one goes up to 11”. Or, perhaps more honestly, 5 dimensions of data. Think for a moment about what’s going on here!
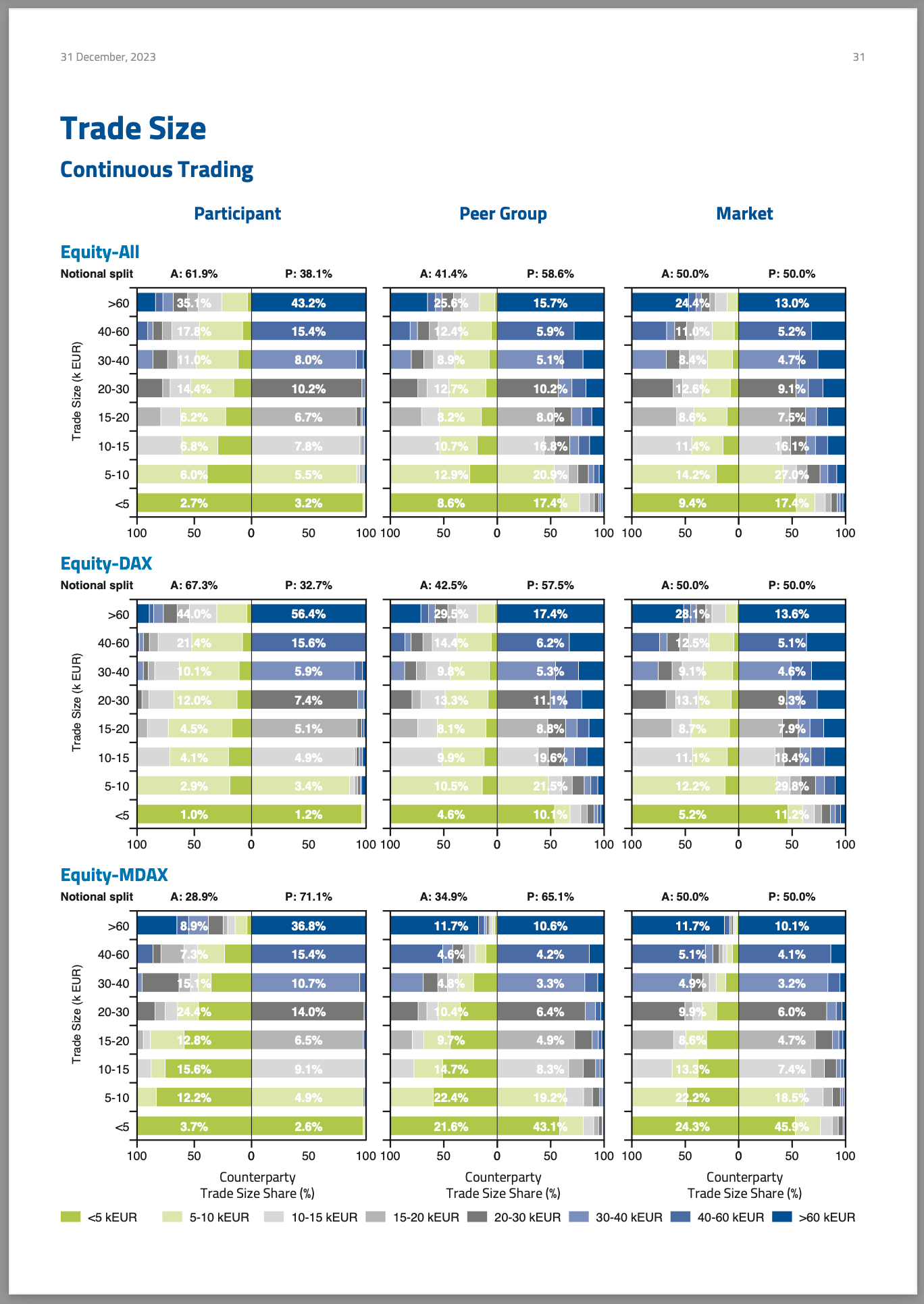
From top to bottom we have different slices of the market - all equities, shares traded on the DAX (the index of largest German companies), shares traded in an index of the next-biggest group of companies (MDAX) and so on. Then, from left to right in each band, we have as usual the participant’s trades, their peer group, and the market as a whole.
Within each of the nine “back to back bar charts” we then have a left-facing set of bars showing aggressive, and right-facing bars showing the passive sides; and within each 8 rows showing the trade sizes.
Each of these rows is in turn divided into coloured slices showing the sizes of those trades.
You may need to be a rocket scientist to understand it, but luckily we didn’t need to be just to plot it! This is a detailed but ultimately straightforward exercise in arranging bar charts and legends. Each of the nine “chart pairs” is really two separate horizontal bar charts, positioned very precisely.
This nicely highlights an important design feature of our library: it was designed from the ground up for precise positioning. We specify the exact bounding box of the chart data, and this doesn’t “wiggle around” when you get longer-than-expected labels or legends or data, nor does it depend (as CSS does) on the thickness of the padding lines. So, we can compose elements safely, set legends to be visible or invisible, and draw extra lines and boxes with precision; and be absolutely sure that each stack of charts is aligned with the ones above and below.
In total, these reports can be produced “in pure code” on a server, without needing to embed different graphics engines inside an outer reporting program, and without needing any “print engines” to convert something else to PDF. Our engine works out where to draw every chart element, just as it works out where to position every word on the page, using the same fonts and colours throughout, and creates the right “page marking operators” which are saved in the PDF file.
So charts exactly match the enclosing documents, we have infinite precision if you zoom in, and create very small file sizes - and - most of all - are generated extremely quickly.
Do they like it?
“We had really, really good feedback from the participants - they like it and XETRA likes it”, says Stefan. “Some comments from our customers included…
… no other exchange offers this …
… what you sent us is amazing …
I’m a little bit impressed.
We outsourced the initial implementation of our chart designs to ReportLab to get to market as quickly as possible. The team delivered great results very quickly and helped us fixing edge cases.”
We are honoured to have been selected to work with one of the world’s top exchanges, and it has been a pleasure to work with Stefan and his team.